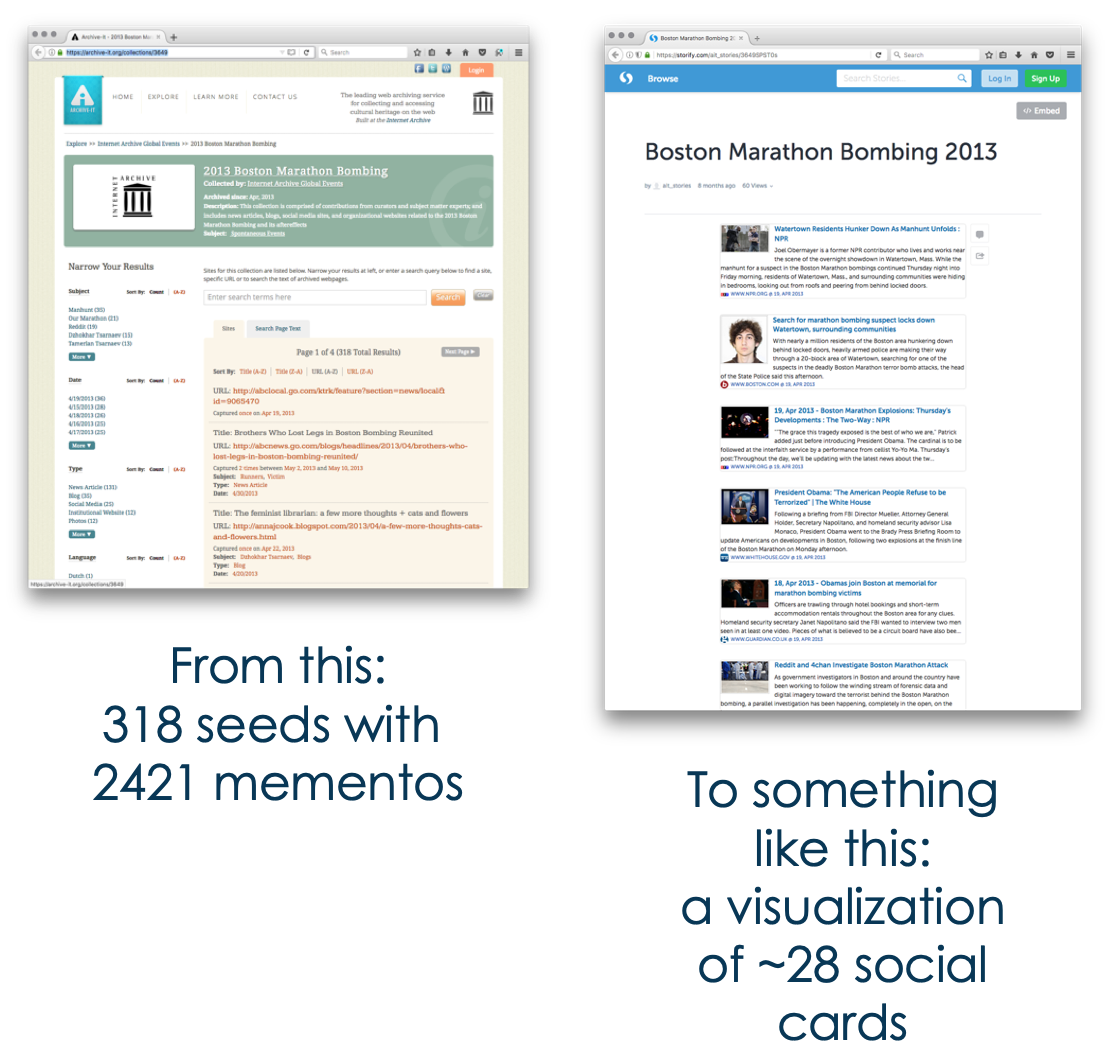
The Goal
The Dark and Stormy Archives (DSA) project exists to provide storytelling solutions to improve the understanding of web archive collections. With search engines, collection users must first have a query in mind. What if the user does not know enough about the collection to form a query? Our goal is to provide a "summary of summaries" in the form of social media storytelling that describes a collection sufficiently for a user to decide if that collection merits further time.
Background

Researchers Create Their Own Web Archive Collections
Historians, social scientists, and journalists use web archives to understand human behavior. Creating collections is not limited to researchers. Organizations archive their own web presence and libraries focus on curating content specific to their communities. These collections gain further value when they are explored again by future users.
These Collections Have Semantic Value
The curators of these collections implied aboutness by centering these collections on a specific topic. Thanks to this work, users of these collections interested in that topic do not need to search the web, or even full web archives, to find a set of pages on that topic.
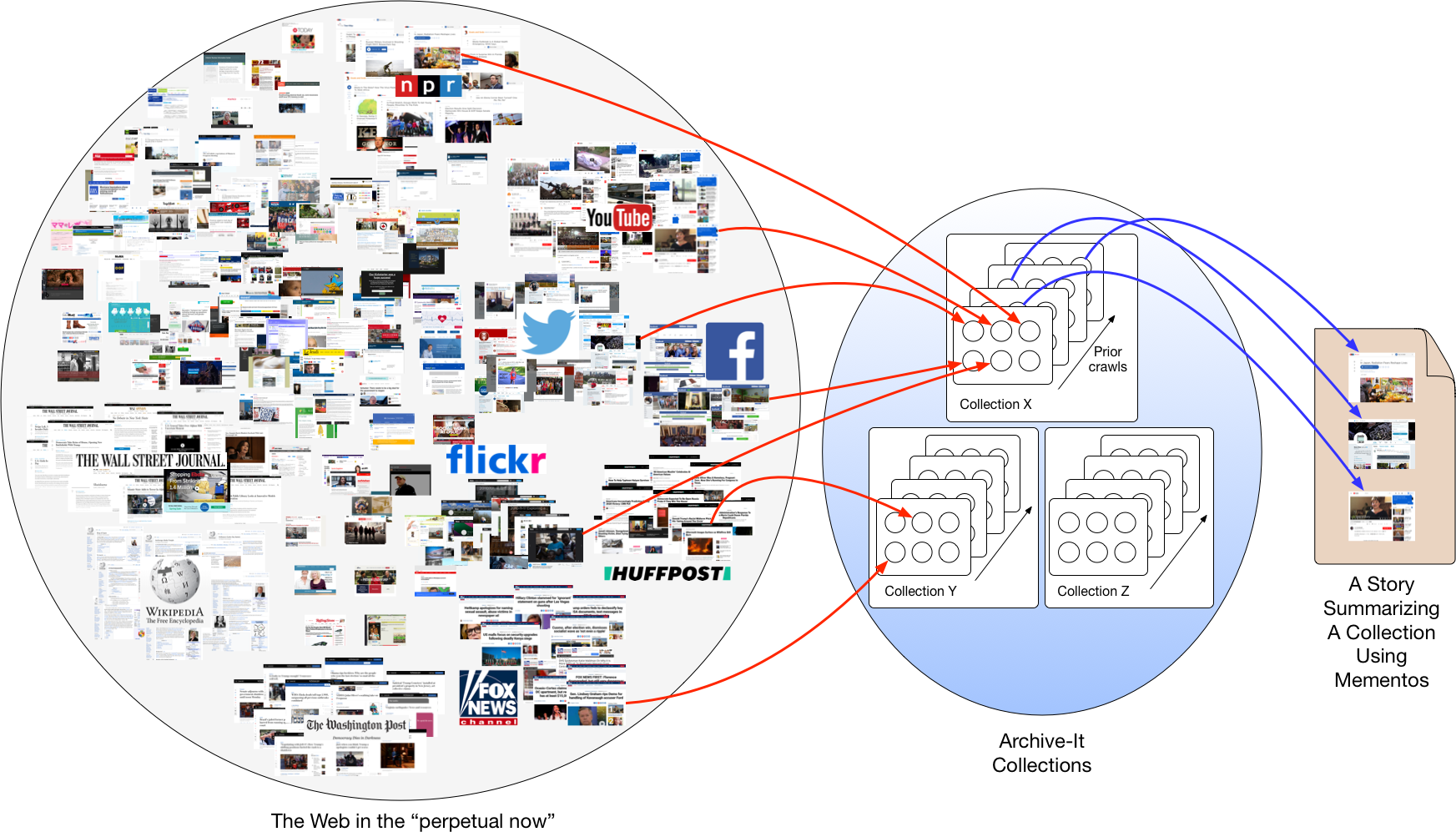
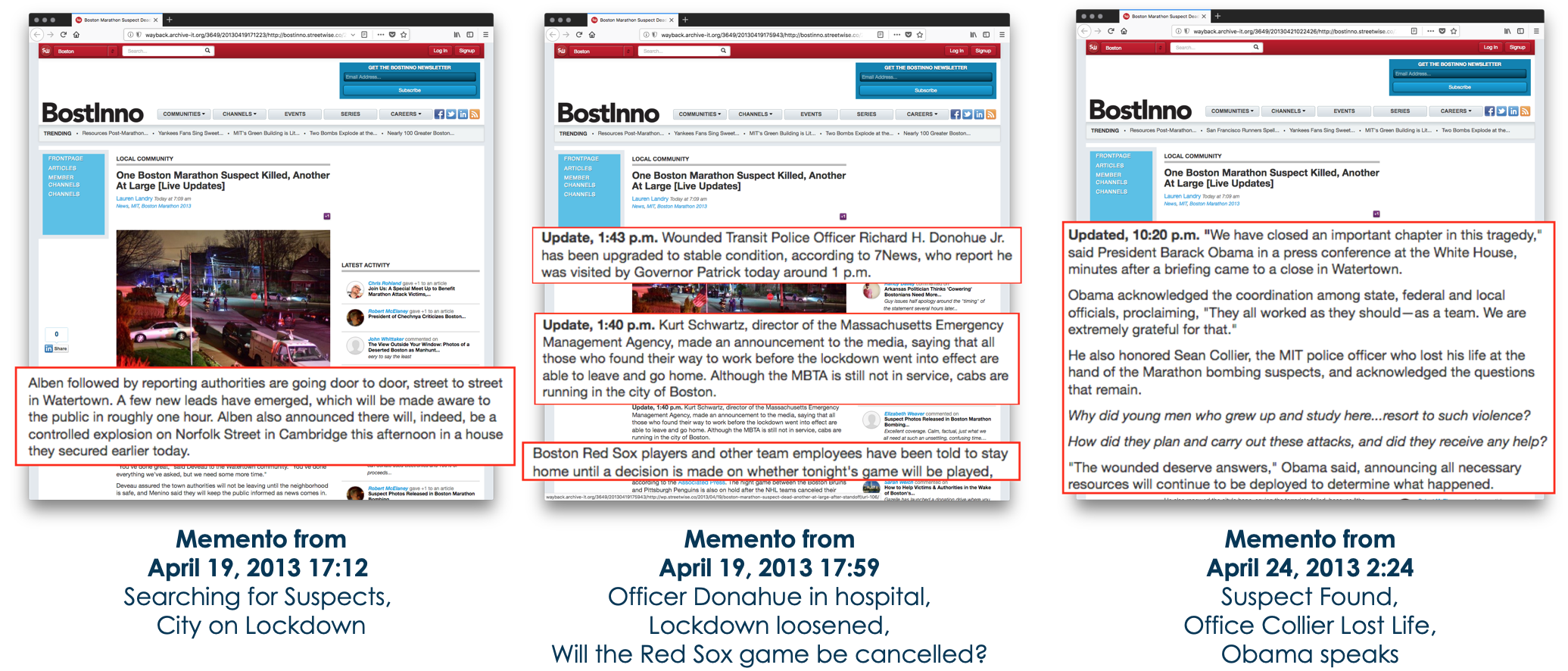
Web Archive Collections Have Many Versions of the Same Page
Web archive collections are different from other document collections because they have different versions of the same page over time. These versions have value because they allow users to see how events unfolded in a news story, or how organizations change over time. This temporal component means that web archive collections require different summarization and visualization techniques than other document collections.
Tools Exist, Allowing for Easy Collection Creation
Tools like Archive-It and Webrecorder exist to allow users to create collections of archived web pages easily. These tools have allowed organizations to easily preserve their history and historians to document events as they unfold.
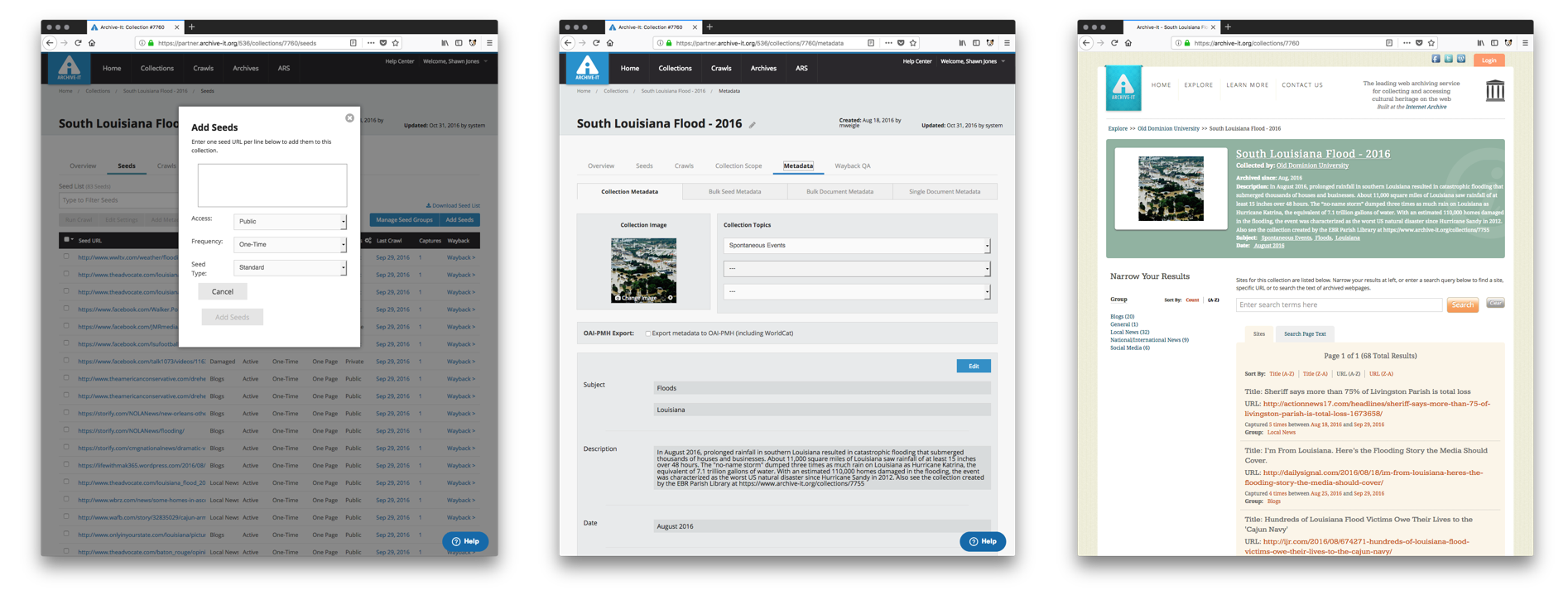
The Problem
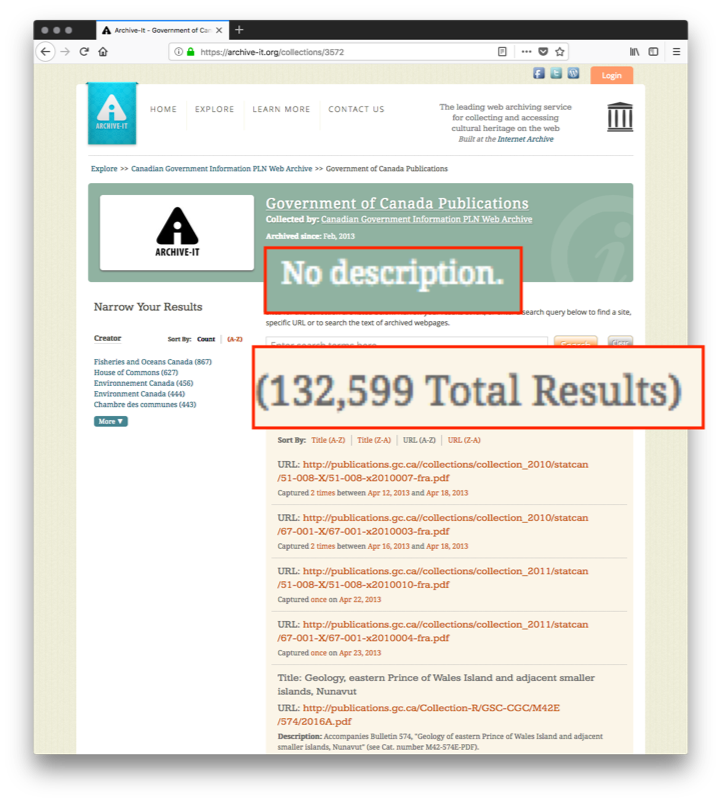
Web Archive Collections Can Be Large
Curators choose web pages as seeds for the web archive collection. Web archives save each version of a web page as a memento. Some collections contain thousands of seeds and every capture of a seed results in one or more mementos. If a potential user wants to review a collection to understand it, they may need to review thousands of mementos.
There Are Multiple Collections About the Same Topic
Because collections are easy to create, there are many collections about the same topic. For example, searches on Archive-It the topic "human rights" results in 31 collections for a user to review.

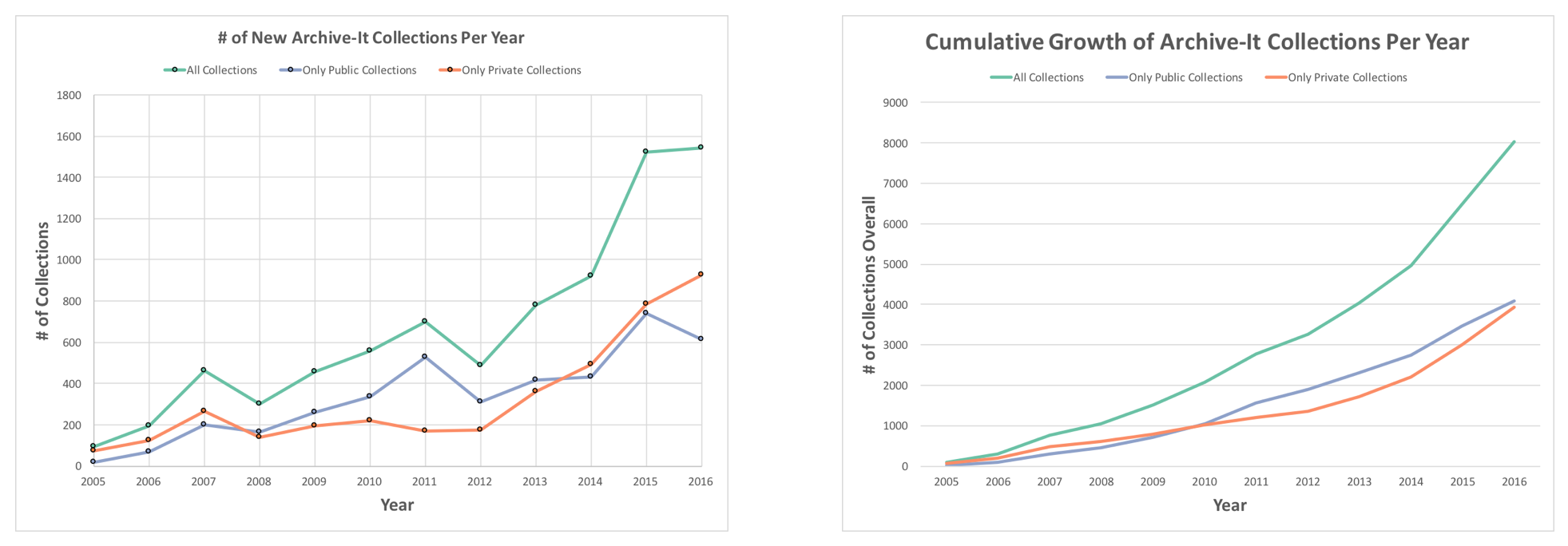
More Collections Are Added Each Year
There were more than 4,000 public Archive-It collections by the end of 2016, and this number has grown to 5,857 by March 2019.
Metadata Exists, But...
With other document collections, metadata is an invaluable tool for understanding the collection and its contents. For example, Encoded Archival Description (EAD) exists for collections, and MAchine-Readable Cataloguing (MARC) exists for books. These standards exist so that users can compare items to each other. Even though Archive-It provides fields from Dublin Core, supplying metadata on individual seeds or a whole collection is optional. When present, the metadata is generated by different curators from different organizations with different content standards and different rules of interpretation. Thus, even when present, users cannot reliably compare metadata on web archive collections in order to understand them.
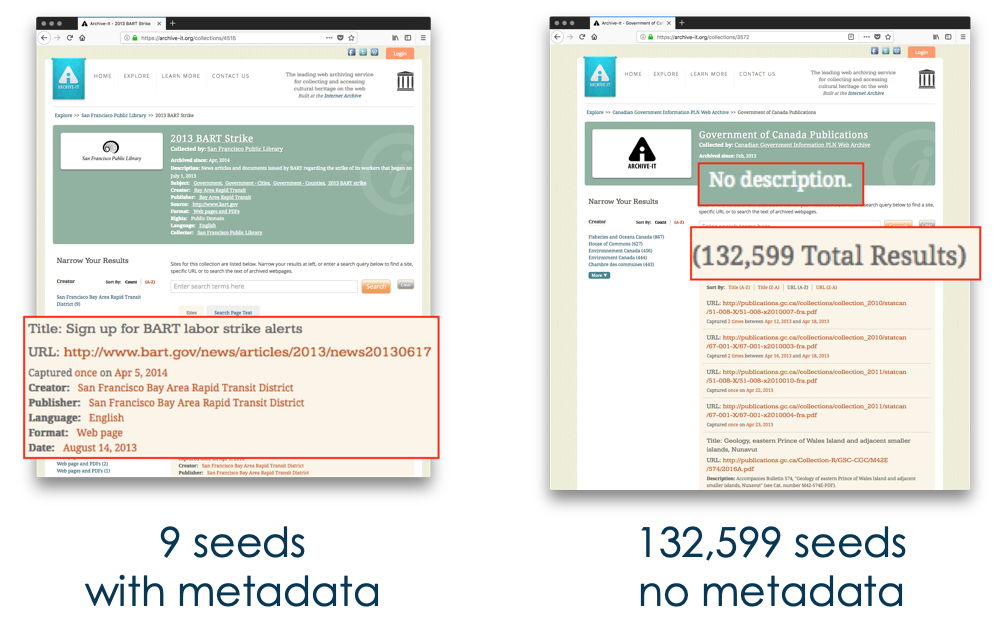
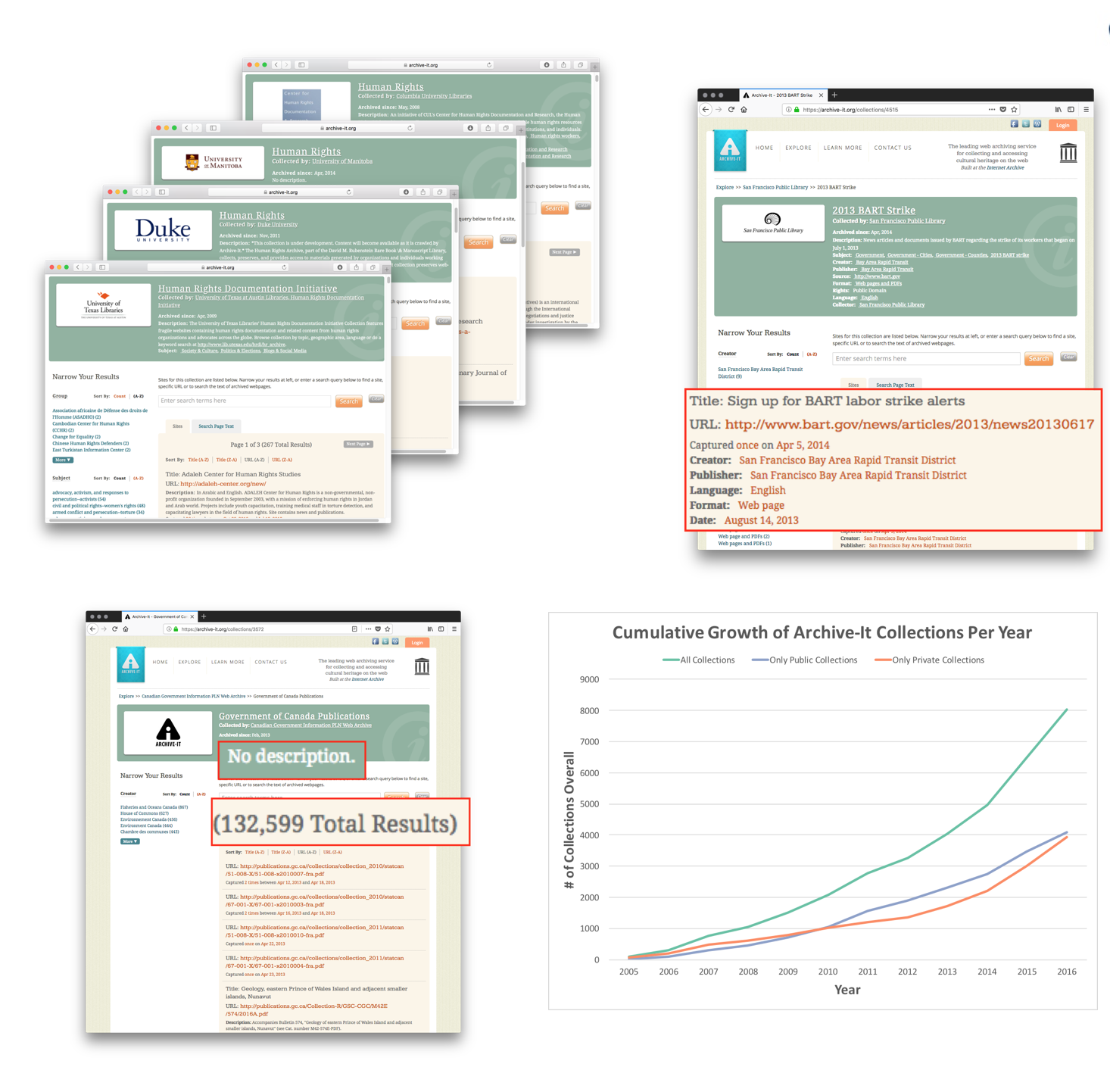
The Problem, Summarized
- There are multiple collections about the same topic.
- The metadata for each collection is non-existent or inconsistently applied.
- Many collections have thousands of seeds with multiple mementos.
- There are thousands of collections.
The Proposal
A Representative Sample Visualized With Social Media Storytelling
We can sample the colleciton to find the mementos that best represent it so that users can understand it. From there, we can visualize the mementos with social media storytelling. Social media storytelling visualizes web pages as surrogates, like cards and browser thumbnails.
A user viewing these stories should now understand the collection well enough to determine if it meets their needs, thus saving them time and effort.